
全国中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2021-05-04 来源:黑马程序员 浏览量:

在网络传输中HTTP协议非常重要,该协议规定了客户端和服务器端请求和应答的标准HTTP协议能保证计算机正确快速地传输超文本文档,并确定了传输文档中的哪部分,以及哪部分内容首先显示(如文本先于图形)等。
根据HTTP协议的规定,客户端发送一个HTTP请求到服务器的请求消息,由请求行,求头部、空行以及请求数据四部分组成。如下所示为请求消息的一般格式。
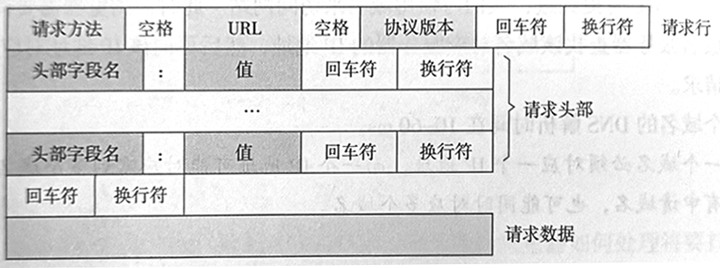
下面结合一个典型的HTTP请求示例,详细介绍HTTP请求信息的各个组成部分。示例内容如下:
GET https://www.baidu.com/content-search.xml HTTP/1.1 Host: www.baidu.com Connection: keep-alive Sec-Fetch-Site: same-origin Sec-Fetch-Mode: no-cors User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36 Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9 Cookie: BIDUPSID=12D4BD8584CA4E016E061A2A996EF369; PSTM=1620090350; BAIDUID=12D4BD8584CA4E01C03BA560AACCF2CE:FG=1; BD_UPN=12314753; H_PS_PSSID=33984_31660_33848_33759_33676_33607_33987_26350; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; __yjs_duid=1_1a965d65ab35181f7b7b98cce26990951620094330751; ab_sr=1.0.0_YjM2Y2YwOWI1MDU4ZDEzODMyZDZkNDBlODllOWEzZTdiMjk4YzgzYmUyM2ZjODA4MWM0MDExZTdiMDZlOTQwOWZhMWI0NGQ3NzNhODI2NTYzMWM1NzQ2ZDBmYjhkM2Q1; ispeed_lsm=0; H_PS_645EC=b177fVn0%2Brl2KczNrCfwRaWGfk3JZzrl7ScjgHBcxVvOkubEWrAPvQ6AXa4; BD_HOME=1; __guid=136081015.3970791550720005000.1620116535606.869; monitor_count=2; BA_HECTOR=8121a4848h8l0k0l6o1g9213e0r
上例中第1行为请求行,包含了请求方法、URL地址和协议版本,代码如下:
GET https://www.baidu.com/content-search.xml HTTP/1.1
其中,GET是请求方法,https://www.baidu com/是URL地址,HTTP/1.1指定了协议版本。
不同的HTTP版本能够使用的请求方法也不同,具体介绍如下:
(1)HTTP 0.9:只有基本的文本GET功能。
(2)HTTP 1.0:完善的请求/响应模型,并将协议补充完整,定义了CET、POST和HEAD3种请求方法。
(3)HTTP 1.1:在1.0基础上进行更新,新增了5种请求方法: OPTIONS、 PUT、 DELETE、TRACE和CONNECT方法。
(4)HTTP 2.0(未普及):请求/响应首部的定义基本没有改变,只是所有首部键必须全部小写,而且请求行要独立为:method、:scheme、:host、 :path 等键值对。
不同请求方法的含义如下所示。
GET
请求指定的页面信息,并返回实体主体
POST
向指定资源提交数据进行处理请求(如提交表单或者上传文件),数据被包含在请求体中。POST 请求可能会导致新的资源的建立和已有资源的修改。
HEAD
类似于GET请求,只不过返回的响应中没有具体内容,用于获取报头
PUT
这种请求方式下,从客户端向服务器传送的数据取代指定的文档内容
DELETE
请求服务器删除指定的页面
CONNECT
HTTP 1.1协议中预留给能够将连接改为管道方式的代理服务器
OPTIONS
允许客户端查看服务器的性能
TRACE
回显服务器收到的请求,主要用于测试或诊断
其中,最常用的请求方法是GET和POST,两者的区别在于:
(1)GET是从服务器上获取指定页面信息,POST是向服务器提交数据并获取页面信息。
(2)GET请求参数都显示在URL上,服务器根据该请求所包含URL中的参数来产生响应内容。由于请求参数都暴露在外,所以安全性不高。
(3)POST请求参数在请求体当中,消息长度没有限制而且采取隐式发送,通常用HTTP服务器提交量比较大的数据(如请求中包含许多参数或者文件上传操作等)。POST请求的参数不在URL中,而在请求体中,在安全性方面,比GET请求更高。

请求行下是若干个请求报头,下面介绍常 用的请求报头及其含义。
(1)Host(主机和端口号) :指定被请求资源的Internet主机和端口号,对应网址URL的Web名称和端口号,通常属于URL的Host部分。
(2)Connection(连接类型):表示客户端与服务器的连接类型。通常情况下,连接类型的对话流程如下:
①Client发起一个包含Connection:keep-alive的请求(HTTP 1.1使用keep-alive为默认值)
②Server收到请求后:
◆如果Server支持keep-alive, 回复一个包含Conection:keep-alive的响应,不关闭连接。
◆如果Server不支持keep-alive,回复一个包含Connection:close的响应,关闭连接。
③如果Client收到包含Connection:keep-alive的响应,则向同个连接发送下一个请求,直到一方主动关闭连接。
注意: Connection:keep-alive 在很多情况下能够重用连接,减少资源消耗,缩短响应时间。例如,当浏览器需要多个文件时(如一个HTML文件和多个Image文件),不需要每次都去请求建立连接
(3)Upgrade-Insecure-Requests(升级为HTTPS请求):表示升级不安全的请求,会在加载HTTP资源时自动替换成HTTPS请求,让浏览器不再显示HTTPS页面中的HTTP请求警报。
HTTPS是以安全为目标的HTTP通道,所以在HTTPS承载的页面上不允许出现HTTP请求,一且出现就会提示或报错。
(4)User-Agent(浏览器名称):标识客户端身份的名称,通常页面会根据不同的User-Agent信息自动做出适配,甚至返回不同的响应内容。
(5)Accept(传输文件类型):指浏览器或其他客户端可以接受的MIME(Multipurpose Internet Mail Extensions,多用途因特网邮件扩展)文件类型,服务器可以根据它判断并返回适当的文件格式。
Accept报头的示例如下:
Accept: */* //1表示什么都可以接收 Accept: image/gif //表明客户端希望接受GIF图像格式的资源 Accept: text/html //表明客户端希望接受html文本 Accept: text/html,application/xhtml+xml;q=0.9,image/*;q=0.8 //表示浏览器支持的MIME类型分别是html文本、xhtml和xml文档、所有的图像格式资深
其中:
◆q:表示权重系数,范围是0=<q<= 1。q值越大,请求越倾向于获得其“;”之前的类型表示的内容。若没有指定q值,则默认为1,按从左到右排序;若被赋值为0,则表示浏览器不接受此内容类型。
◆text: 用于标准化地表示文本信息,文本信息可以是多种字符集和多种格式。
◆Aplication:用于传输应用程序数据或者二进制数据。
(6)Referer(页面跳转来源):表明产生请求的网页来自于哪个URL。用户是从该Referer页面访问到当前请求的页面。这个属性可以用来跟踪Web请求来自哪个页面,是从什么网站来的等。
有时下载某网站的图片时,需要对应Referer,否则无法下载图片,那是因为做了防盗链。原理就是根据Referer去判断URL是否是本网站的地址,如果不是,则拒绝:如果是,就可以下载。
(7)Accept-Encoding(文件编解码格式):指出浏览器可以接受的编码方式。编码方式不同于文件格式,其作用是压缩文件并加速文件传递速度。浏览器在接收到Web响应之后先解码,然后再检查文件格式,许多情形下可以减少大量的下载时间。例如:
Accept-Encoding:gzip;q=1.0, identity; q=0.5, *;q=0
如果有多个Enoding同时匹配,按照q值顺序排列,本例中按顺序支持gip、identity压缩编码,支持gzip的浏览器会返回经过gzip编码的HTML页面。
如果请求消息中没有设置这个报头,通常服务器假定客户端不支持压缩,直接返回文本。
(8)Accept-Language(语言种类):指出浏览器可以接受的语言种类,如en或en-us指英语,zh或zh--cn指中文,当服务器能够提供一种以上的语言版本时要用到。
如果目标网站支持多个语种,可以使用这个信息来决定返回什么语言的网页。
(9)Accepl-Charset (字符编码) :指出浏览器可以接受的字符编码。例如:
Accept-Charset:iso-8859-1,gb2312,utf-8
常用的字符编码包括:
◆iso-8859-1:通常称为Latin-1。Latin-1包括书写所有西方欧洲语言不可缺少的附加字符,英文浏览器的默认值是iso-8859-1。
◆gb2312:标准简体中文字符集。
◆utf-8: Unicode的一种变长字符编码, 可以解决多种语言文本显示问题,从而实现应用国际化和本地化。
如果在HTTP请求消息中没有设置这个域,默认情况下,客户端可以接受任何字符集,返回的是网页charset指定的编码。
(10)Cookie(Cookie):浏览器用这个属性向服务器发送Cookie。Cookie 是在浏览器中寄存的小型数据体,它可以记载和服务器相关的用户信息,也可以用来实现模拟登录。
(11)Conten-Type(POST数据类型):指定POST请求中用来表示的内容类型。例如:
Content-Type=Text/XML; charset=gb2312:
上述示例指明了该请求的消息体中包含的是纯文本的XML类型的数据,字符编码采用gb2312。
猜你喜欢:




















.jpg)