
全国中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2022-01-05 来源:黑马程序员 浏览量:
Sqoop是Apache旗下的一款开源工具,该项目开始于2009年,最早是作为Hadoop的一个第三方模块存在,后来为了让使用者能够快速部署,也为了让开发人员能够更快速的迭代开发,并在2013年,独立成为Apache的一个顶级开源项目。
Sqoop主要用于在Hadoop和关系数据库或大型机之间传输数据,可以使用Sqoop工具将数据从关系数据库管理系统导入(import)到Hadoop分布式文件系统中,或者将Hadoop中的数据转换导出(export)到关系数据库管理系统,其功能如下图所示。
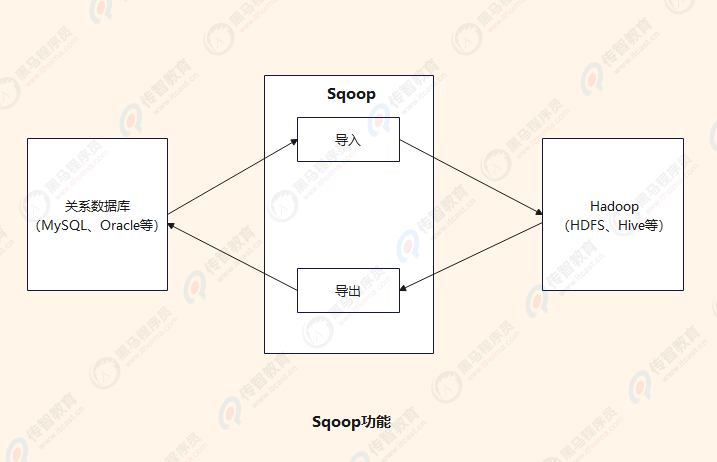
目前Sqoop主要分为Sqoop1和Sqoop2两个版本,其中,版本号为1.4.x属于Sqoop1,而版本号为1.99.x的属于Sqoop2。这两个版本开发时的定位方向不同,体系结构具有很大的差异,因此它们之间互不兼容。
Sqoop1功能结构简单,部署方便,提供命令行操作方式,主要适用于系统服务管理人员进行简单的数据迁移操作;Sqoop2功能完善、操作简便,同时支持多种访问模式(命令行操作、Web访问、Rest API),引入角色安全机制增加安全性等多种优点,但是结构复杂,配置部署更加繁琐。
Sooop是传统关系数据库服务器与Hadoop间进行数据同步的工具,其底层利用MapReduce并行计算模型以批处理方式加快了数据传输速度,并且具有较好的容错性功能,工作流程如下图所示。
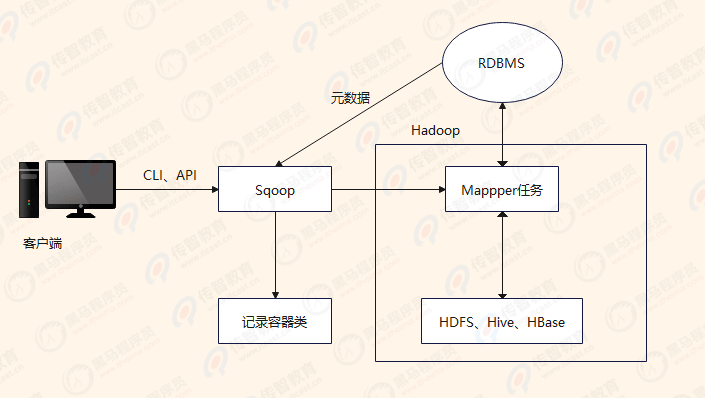
Sqoop工作流程
从上图中可以看出,通过客户端CLI(命令行界面)方式或Java API方式调用Sqoop工具,Sqoop可以将指令转换为对应的MapReduce作业(通常只涉及Map任务,每个Map任务从数据库中读取一片数据,这样多个Map任务实现并发地复制,可以快速地将整个数据复制到HDFS上),然后将关系数据库和Hadoop中的数据进行相互转换,从而完成数据的迁移。
可以说,Sqoop是关系数据库与Hadoop 之间的数据桥梁,这个桥梁的重要组件是Sgoop连接器,它用于实现与各种关系数据库的连接,从而实现数据的导人和导出操作。
Sqoop连接器能够支持大多数常用的关系数据库,如MySQL、Oracle、DB2和SQL Server等,同时它还有一个通用的JDBC连接器,用于连接支持JDBC协议的数据库。
1.导入原理
在导人数据之前,Sqoop使用JDBC检查导人的数据表,检索出表中的所有列以及列的SQL数据类型,并将这些SQL类型映射为Java数据类型,在转换后的MapReduce应用中使用这些对应的Java类型来保存字段的值,Sqoop的代码生成器使用这些信息来创建对应表的类,用于保存从表中抽取的记录。
2.导出原理
在导出数据之前,Sqoop会根据数据库连接字符串来选择一个导出方法,对于大部分系统来说,Sqoop会选择JDBC。Sqoop会根据目标表的定义生成一个Java类,这个生成的类能够从文本中解析出记录数据,并能够向表中插人类型合适的值,然后启动一个MapReduce作业,从HDFS中读取源数据文件,使用生成的类解析出记录,并且执行选定的导出方法。
猜你喜欢:




















.jpg)