
全国中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2022-03-25 来源:黑马程序员 浏览量:
MongoDB数据库提供了多样性的索引支持,因此可以提高查询集合中文档的效率。若是没有索引,MongoDB数据库必须执行全集合扫描(即扫描集合中的每一个文档),从而筛选出与查询条件相匹配的文档。这种扫描全集合的查询效率是非常低的,尤其是在处理海量数据时,执行查询操作需要花费几十秒甚至几分钟的时间,这无疑对网站的性能是非常致命的。若是执行查询操作时,集合中的文档存在适当的索引,MongoDB就可以使用该索引限制必须检查的文档数量。
索引是一种特殊的数据结构,即采用B-Tree数据结构。索引是以易于遍历读取的形式存储着集合中文档的一小部分,文档的一小部分指文档中的特定字段或一/多组字段,并且这些字段均按照字段的值进行排序。索引项的排序支持有效的等值匹配和基于范围的查询操作。此外,MongoDB还可以使用索引中的排序返回排序的结果。
MongoDB的索引可以分为六种,即单字段索引、复合索引、多键索引、地理空间索引、全文本索引以及哈希索引,六种索引的详细介绍,具体如下:
MongoDB支持在文档的单个字段上创建用户定义的升序/降序索引,因此被称为单字段索引(SingleFieldIndex)。默认情况下,MongoDB中所有集合在“_id”字段上都有一个索引,当然,用户也可以根据自己的需求添加额外索引来支持重要的查询和操作。由于MongoDB可以从任何方向遍历索引,因此对于单个字段索引和排序操作来说,索引项的排序顺序(即升序或降序)并不重要。
下面,我们通过一张图来介绍单字段索引,具体如图3-27所示。
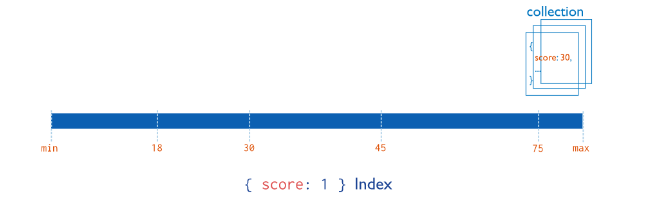
图3-27单字段索引
从图3-27可以看出,在集合collection中的字段score上创建了一个索引,并指定其为有序。若是查询字段score为30的文档,则可以先在索引中找到score为30的索引,然后再从真实的集合collection中找到字段score为30的文档。因此,在单字段索引中,无论字段score为1(升序)或者-1(降序)对文档的查询效率均无影响。
下面,我们通过一张图来介绍复合索引,具体如图3-28所示。

图3-28复合索引
从图3-28可以看出,复合索引是由{userid:1,score:-1}组成的,因此复合索引首先按字段userid进行升序排序,然后在每个字段userid的值内,按照score降序排序。
若文档中的字段为数组类型,则每个字段都是数组中的一个元素,MongoDB将会为数组中的每个元素创建索引,因此被称为多键索引(Multikey Index)。多键索引允许通过匹配数组的一个或多个元素来查询包含该数组的文档。如果索引字段包含数组值,则MongoDB会自动确定是否创建多键索引,而无需显式地指定创建多键索引。
下面,我们通过一张图来介绍多键索引,具体如图3-29所示。

图3-29多键索引从图3-29可以看出,集合collection中文档字段addr是一个数组类型,数组值包含两个元素,分别是{zip:“10036”,...}和{zip:“94301”,...}。因此,MongoDB会自动创建多键索引,即{“addr.zip”:1}。
为了支持对地理空间坐标数据的有效查询,MongoDB提供了两种特殊的索引,即返回结果时使用平面几何的二维索引(2d索引)和返回结果时使用球面几何的二维球面索引(2dsphere索引)。其中,2d索引支持在欧几里德平面上的计算,也支持计算球面上的距离;2dsphere索引支持球面上几何计算的查询,包含查询(在一个指定多边形内的位置进行查询)、交集查询(查询指定几何相交的位置)和临近查询(如查询离另一个点最近的点)。我们可以通过将2d索引和2dsphere索引进行相结合,从而进行高效的地理空间查询。
MongoDB提供了一种文本索引类型,支持在集合中搜索字符串内容,即进行文本检索查询。文本索引不存储特定语言的停止词,例如“the”、“a”以及“or”等词,而是将集合中的词作为词干,只存储根词。为了执行文本检索查询,则集合上必须有一个text索引。一个集合只能拥有一个文本检索索引,但是这个索引可以覆盖多个字段。
为了支持基于哈希分片键进行分片,MongoDB提供了哈希索引类型。哈希索引是使用哈希函数来计算索引字段的哈希值,若是该索引字段的哈希值在哈希索引的范围内,则分布的更加随机。需要注意的是,哈希索引只支持等值匹配,不支持基于范围的查询。
猜你喜欢:




















.jpg)